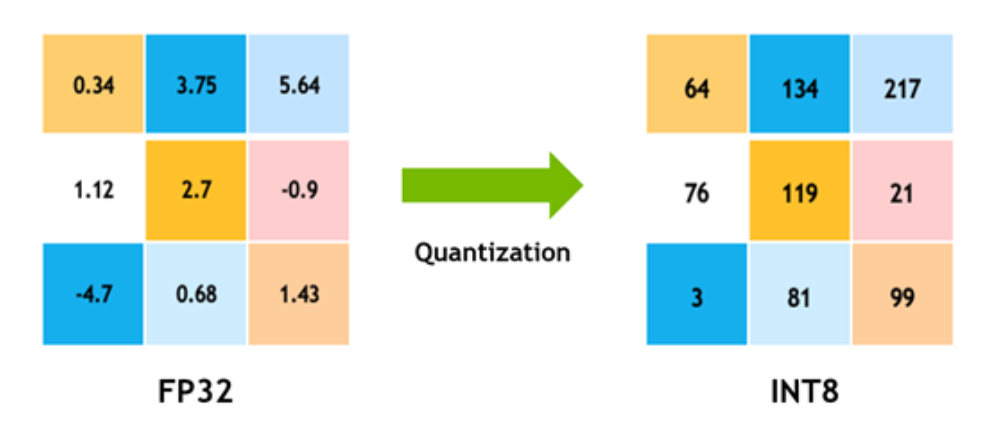
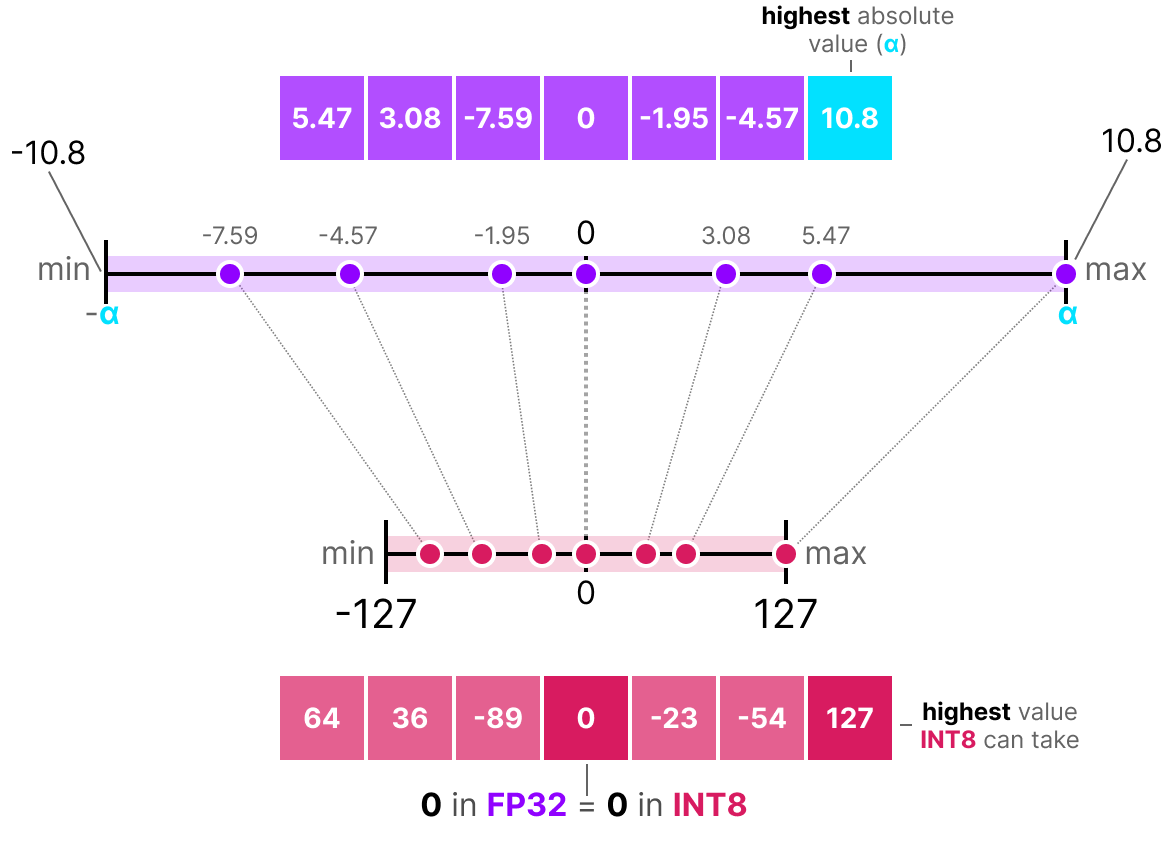
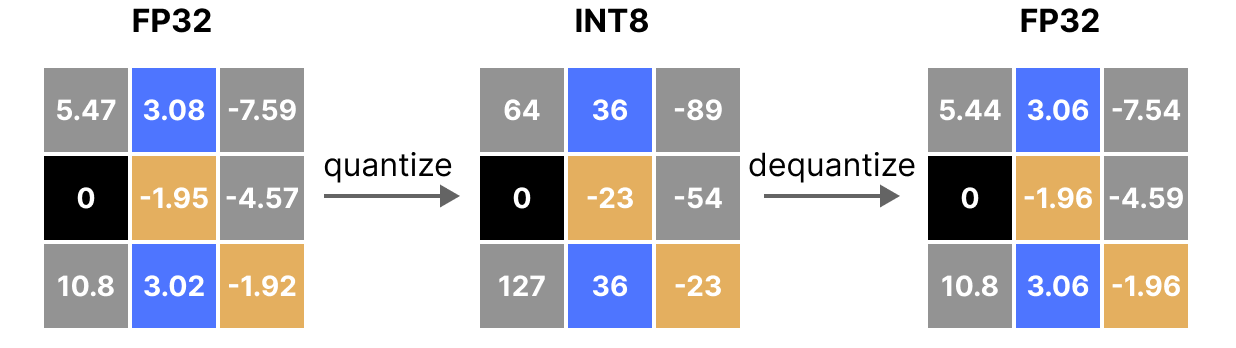
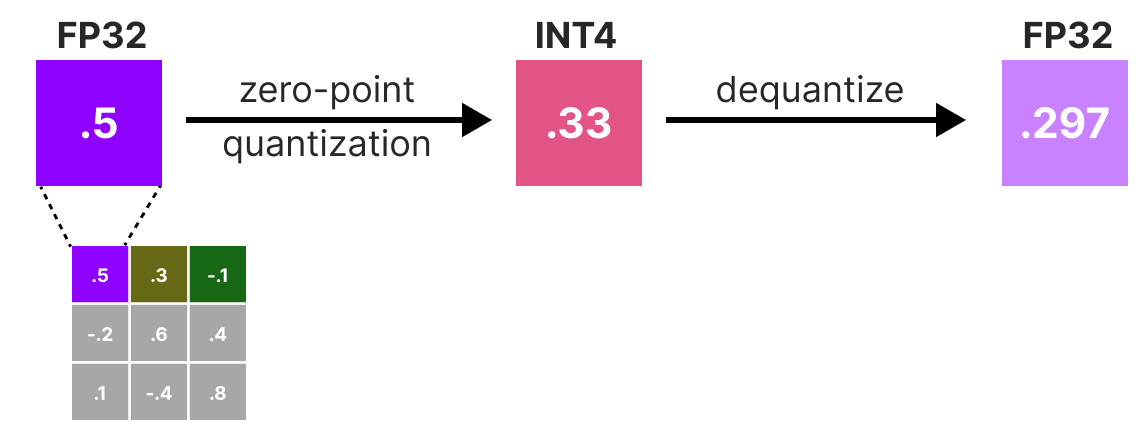
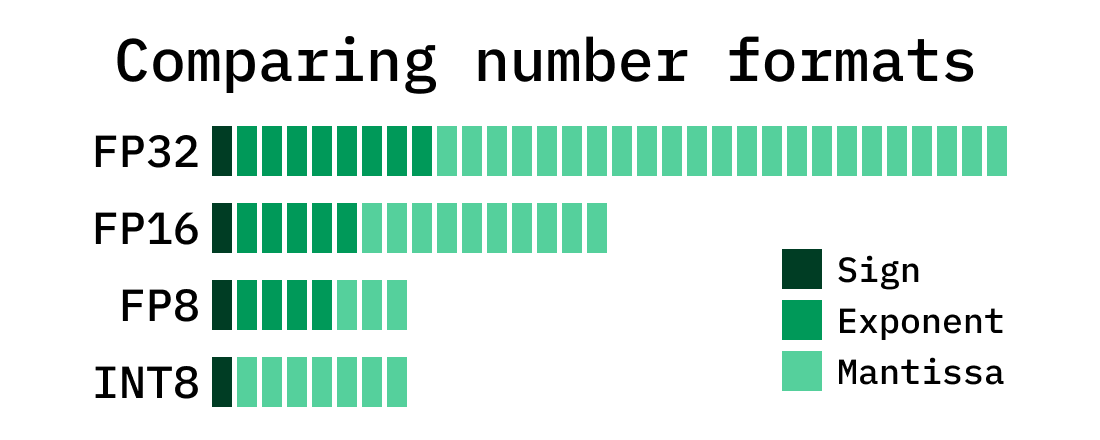
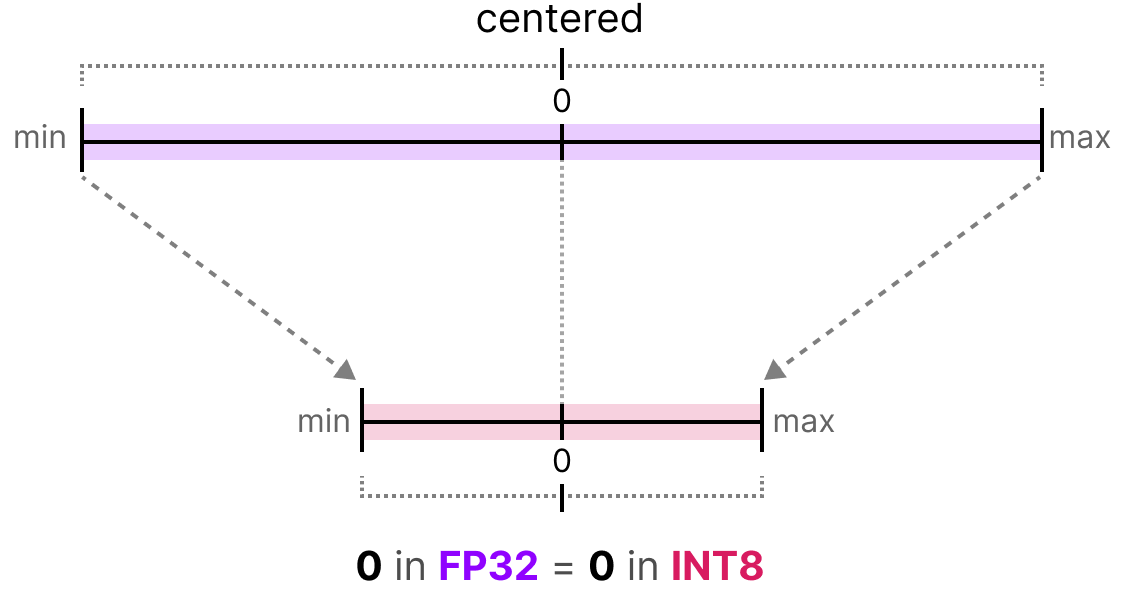
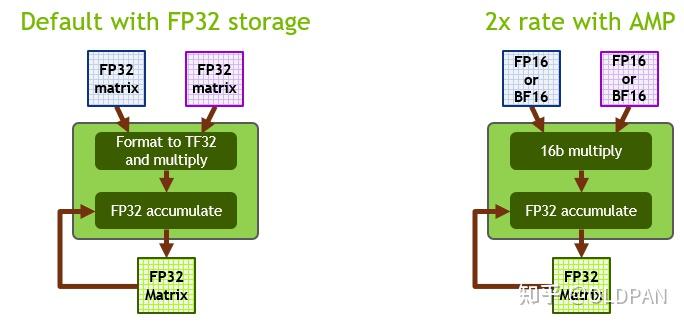
Showing 107 of 107on this page. Filters & sort apply to loaded results; URL updates for sharing.107 of 107 on this page
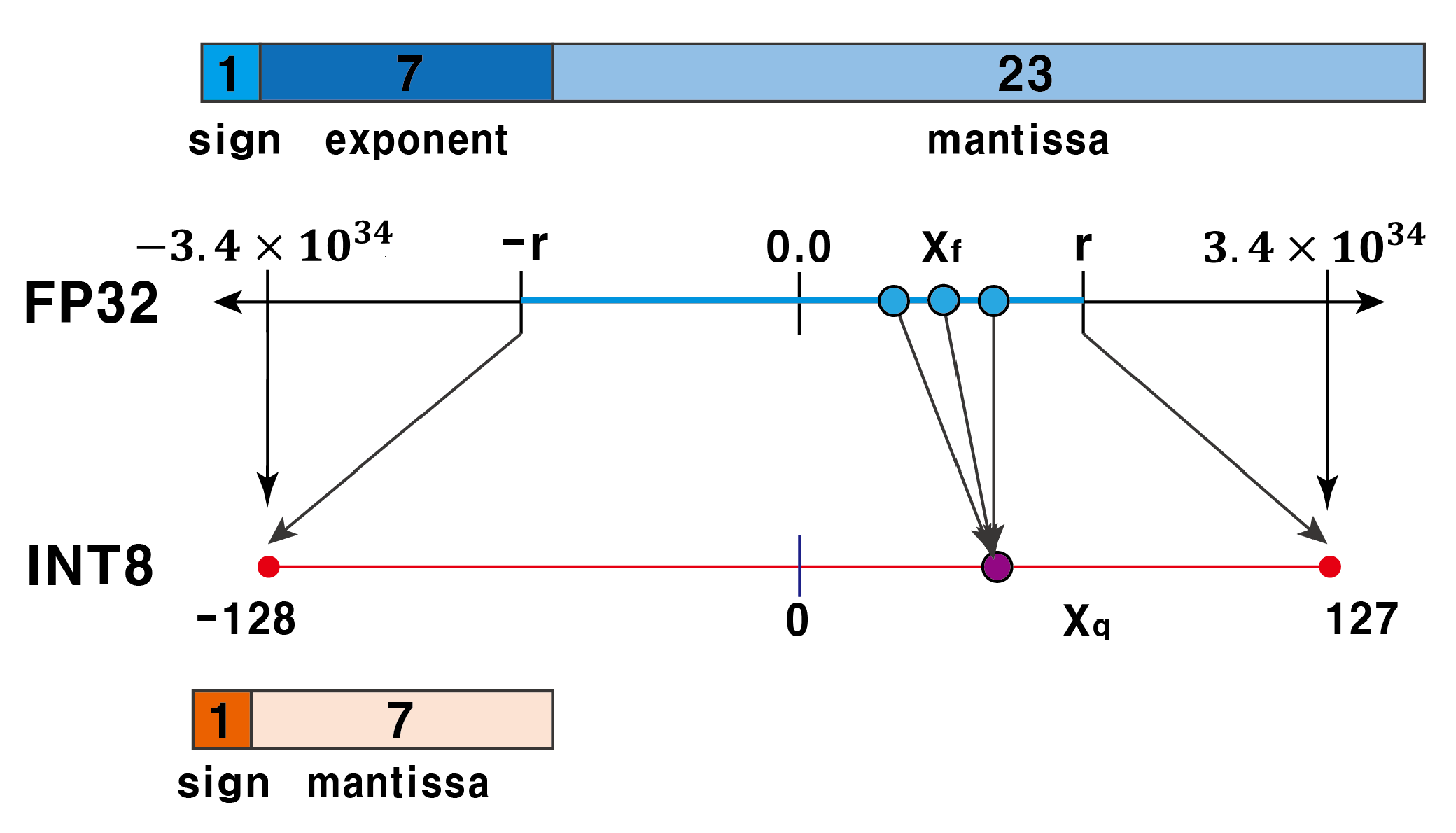
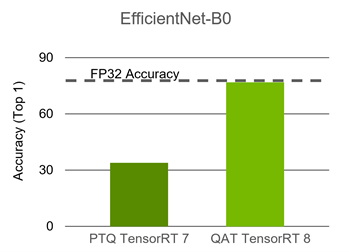
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
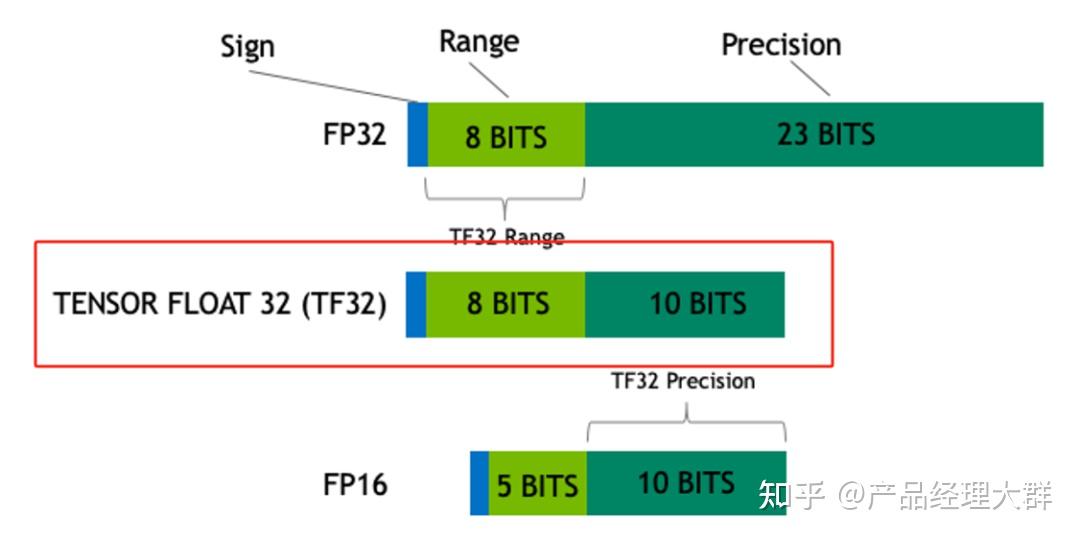
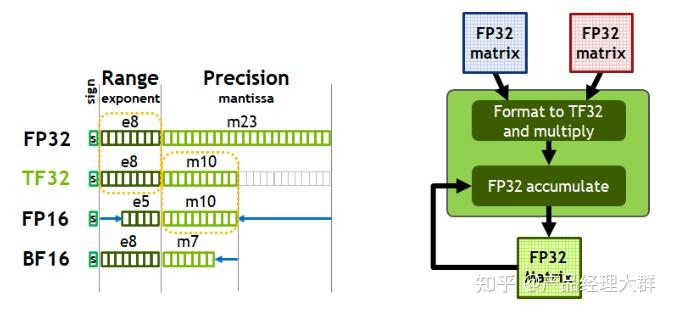
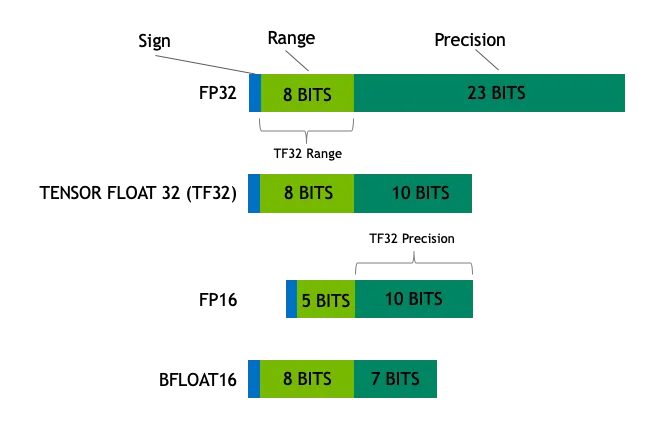
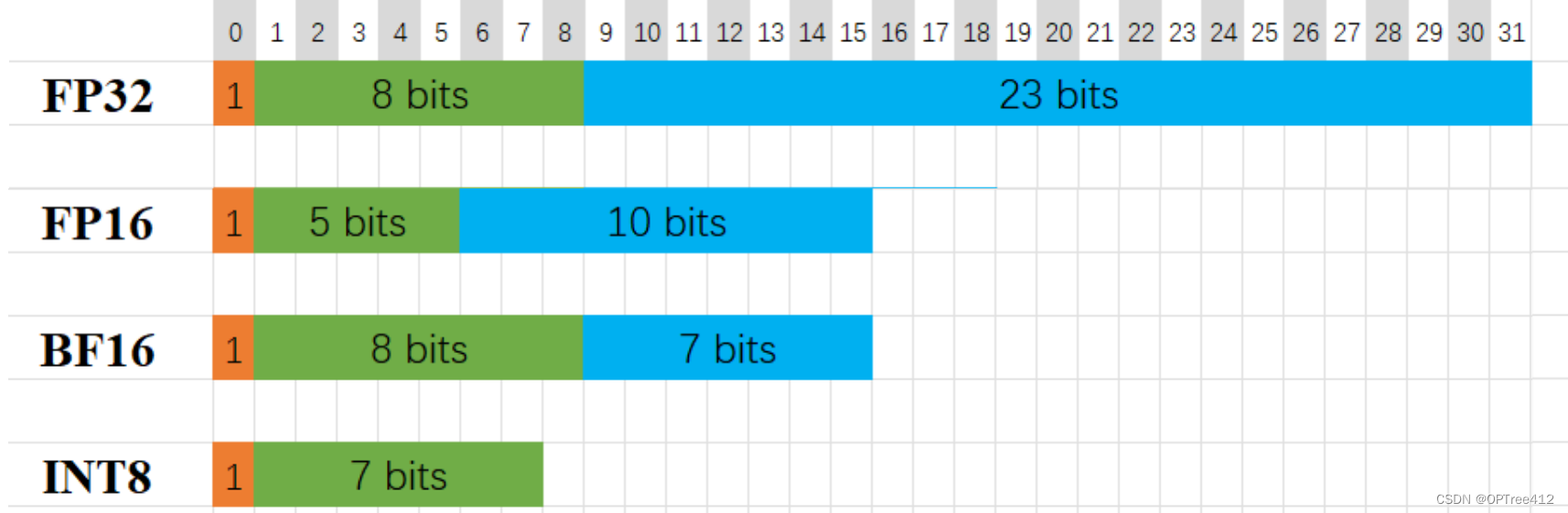
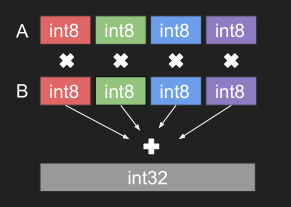
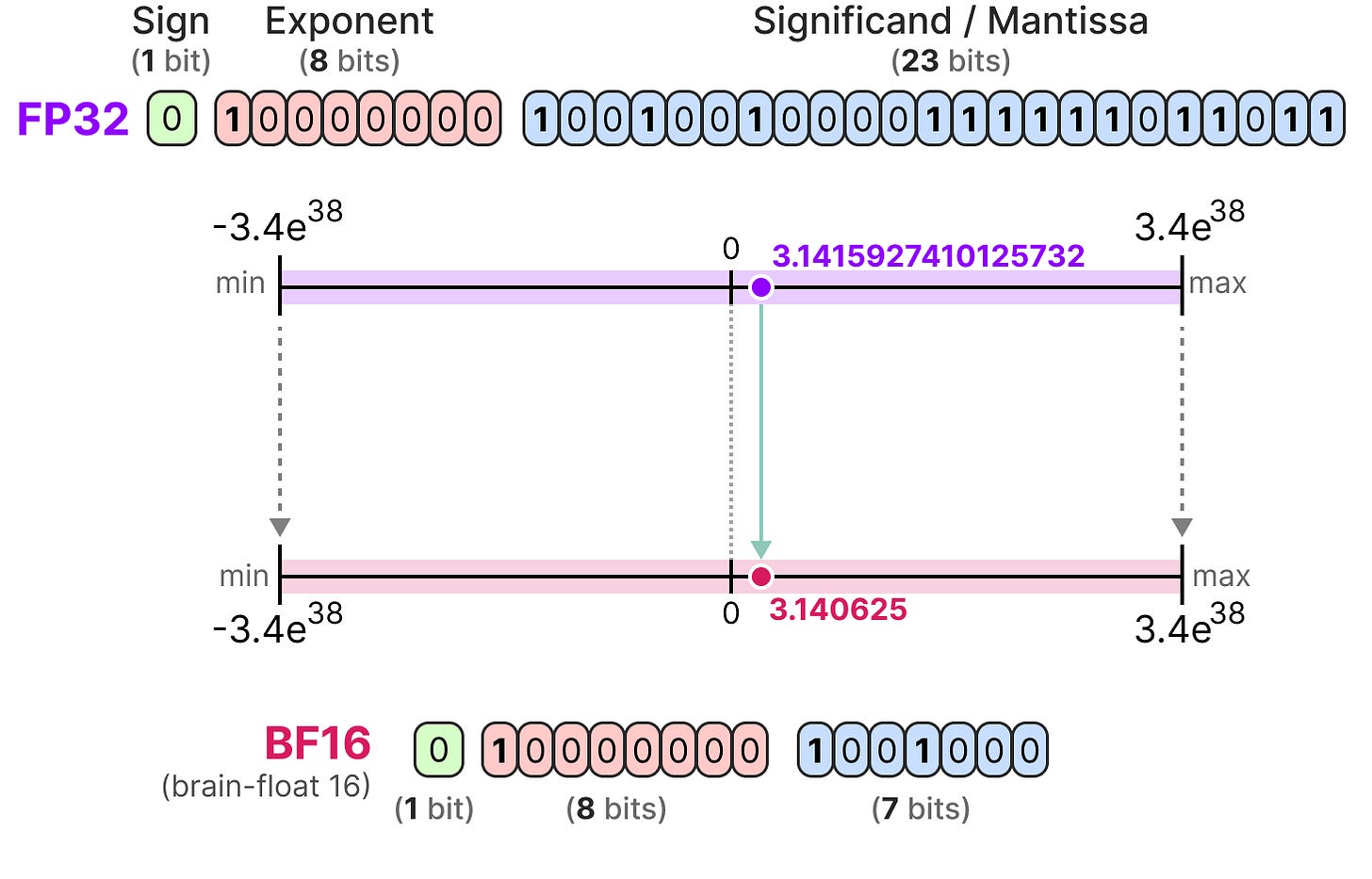
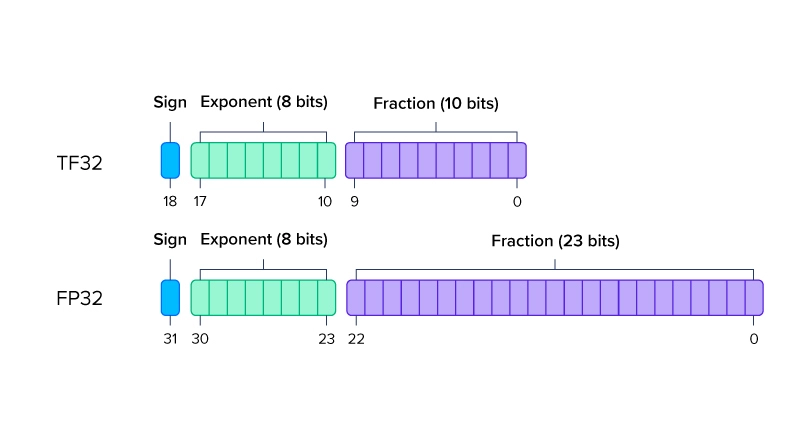
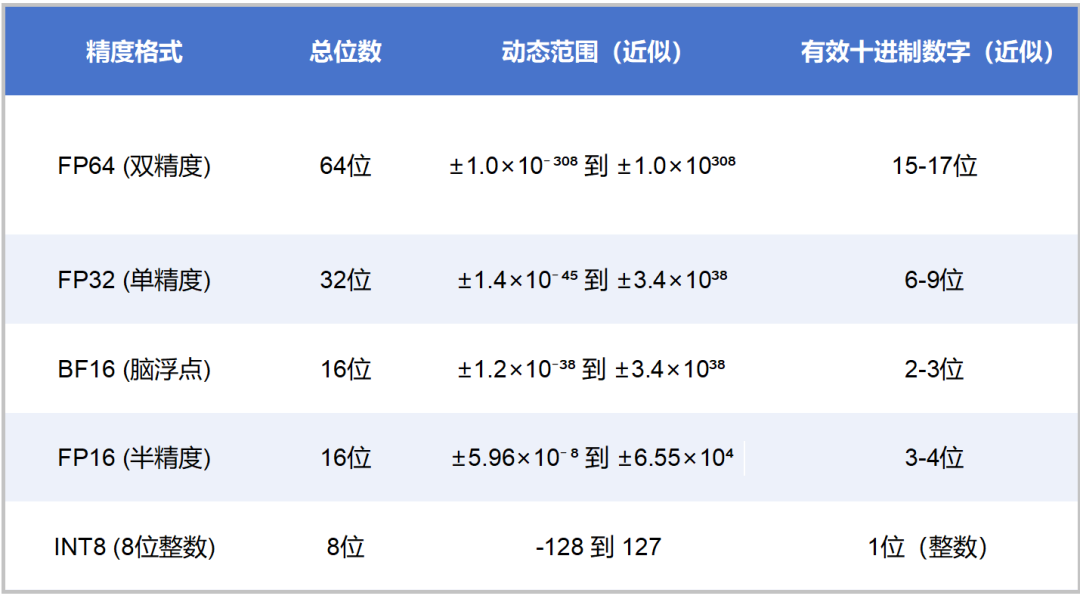
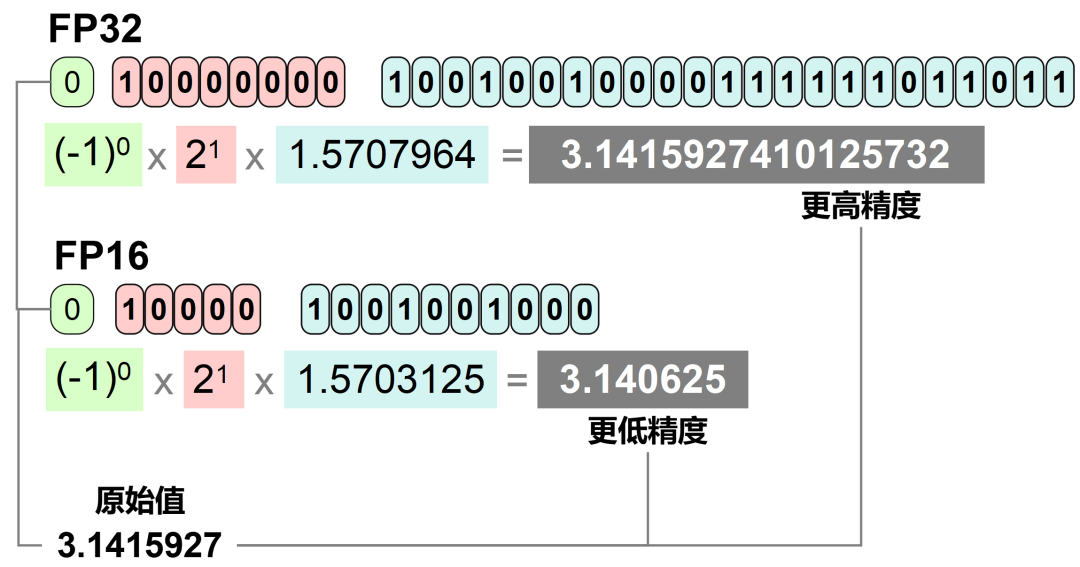
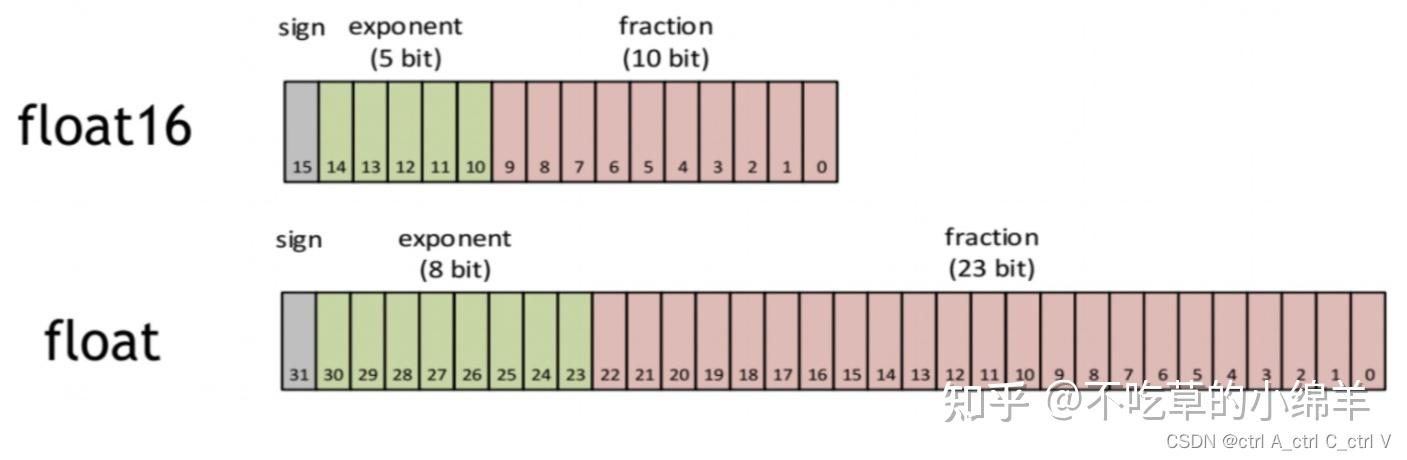
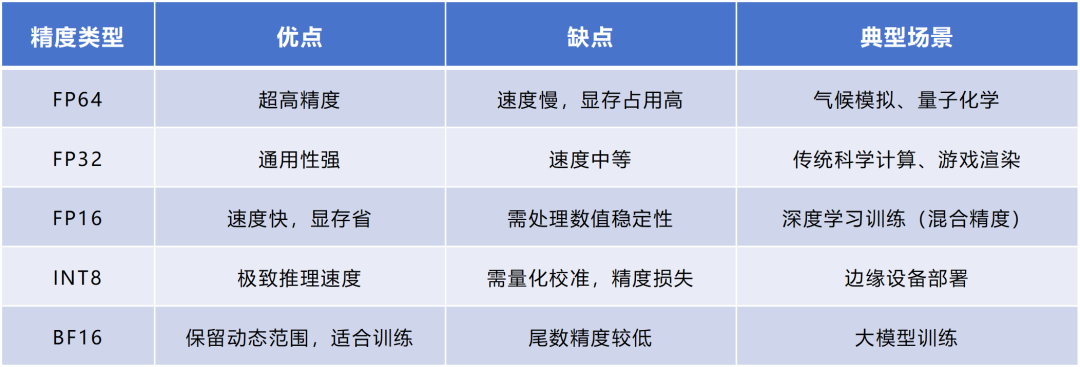
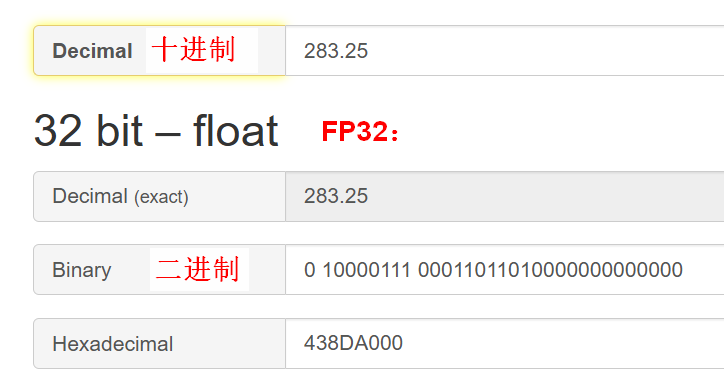
Precision Comparison: FP64 FP32 FP16 TF32 BF16 INT8
利用 NVIDIA TensorRT 量化感知训练实现 INT8 推理的 FP32 精度 - 广州市迈进信息科技有限公司/研云创服务器
Accuracy comparison between FP32 and INT8 in different layers with ...
深度学习模型权重数值精度FP32,FP16,INT8数值类型区别_fp16 fp32 int8 int16-CSDN博客
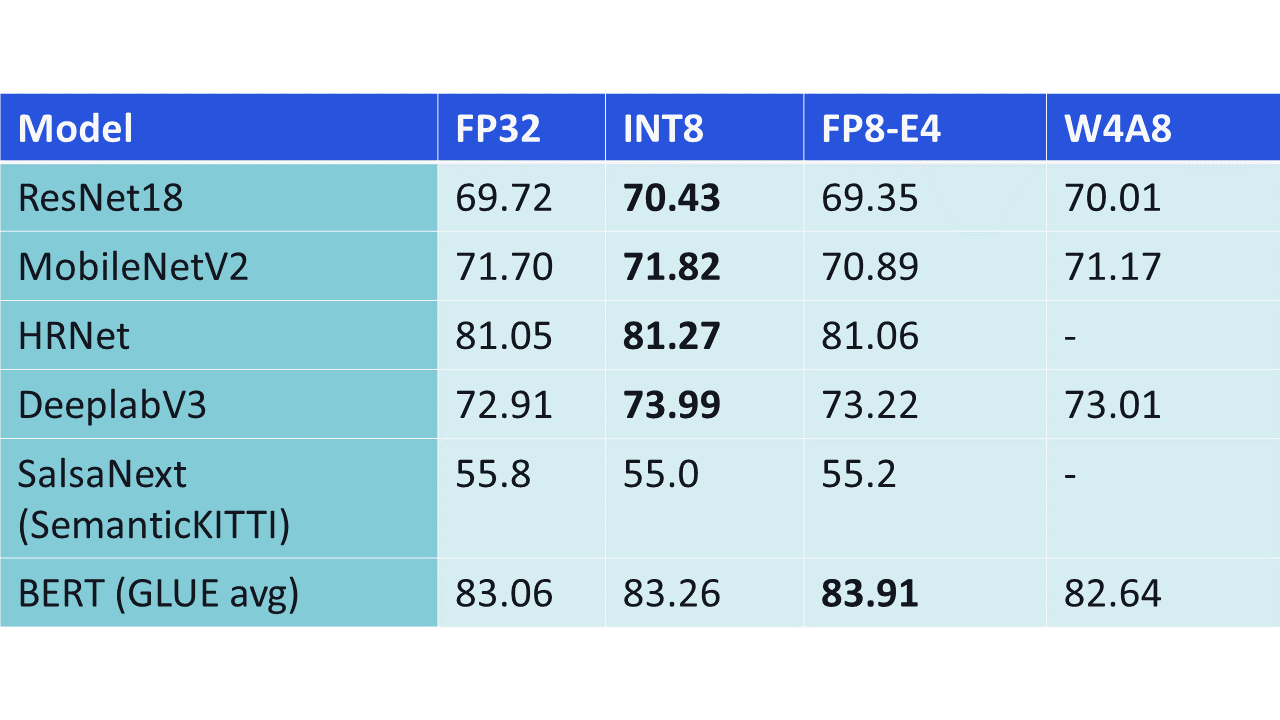
Performance metrics of different models with FP16, FP32 and INT8 ...
Accuracy comparison between FP32 and INT8 in different layers ...
YOLOv8 Classification Model from FP32 to FP16 and INT8 · Issue #10397 ...
Choose FP16, FP32 or int8 for Deep Learning Models
模型精度量化:从 FP32 到 INT8 的技术路径 - 知乎
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
【AI系统】低比特量化原理_ai fp16 int8 量化-CSDN博客
FP32、FP16和INT8_atlas int8 fp16 fp32算力转换-CSDN博客
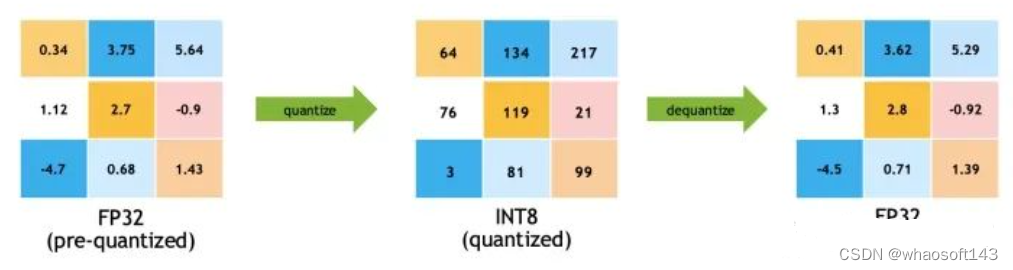
Quantization from FP32 to INT8. | Download Scientific Diagram
YOLOv5 Model INT8 Quantization based on OpenVINO™ 2022.1 POT API ...
Improve Inference with INT8 Quantization for x86 CPU in PyTorch
Numerical Precision in Machine Learning: FP16, FP32, and INT8 | by ...
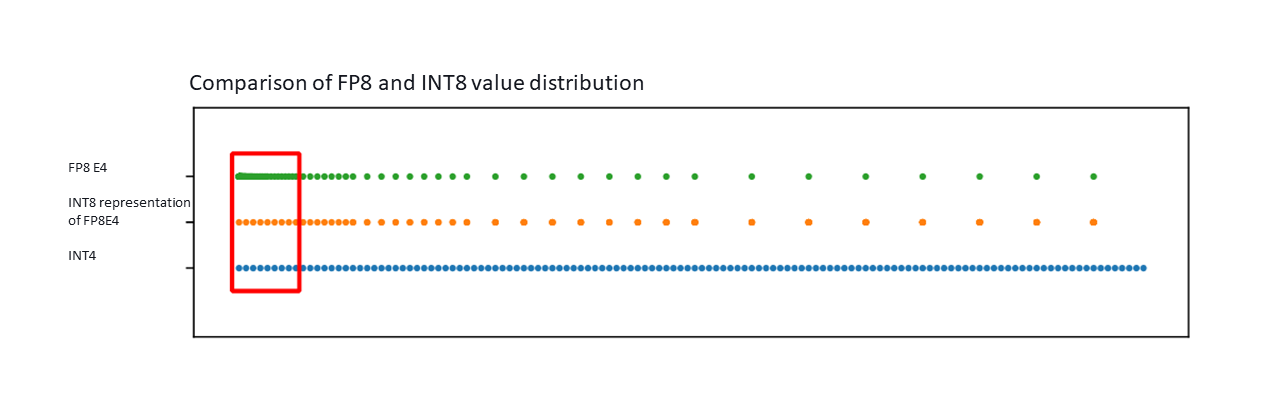
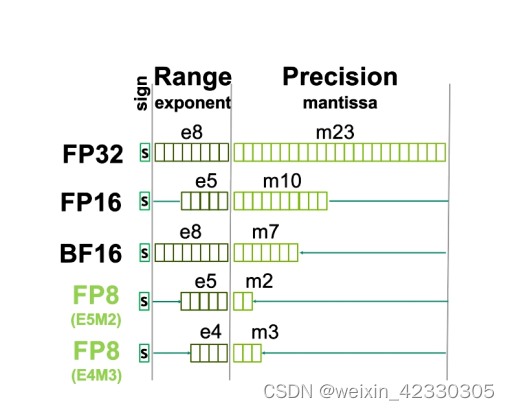
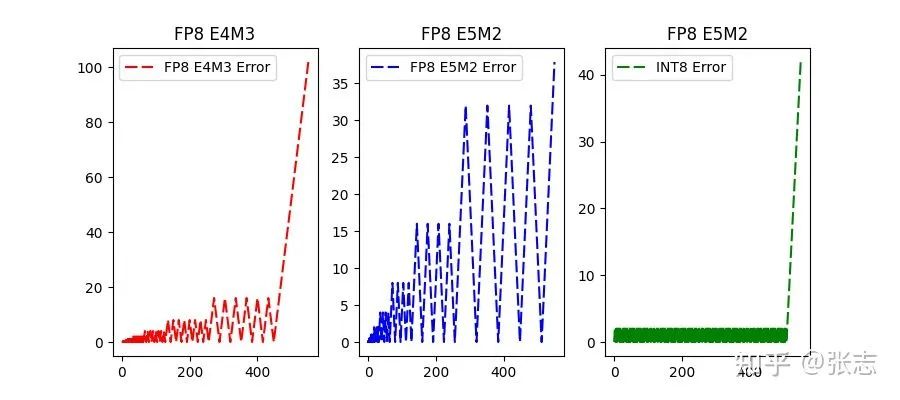
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Yolov8 .pt model to FP32, INT8 IR conversion · Issue #7631 ...
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
Unlocking LLM Performance: Advanced Quantization Techniques on Dell ...
Small numbers, big opportunities: how floating point accelerates AI and ...
A Hands-On Walkthrough on Model Quantization - Medoid AI
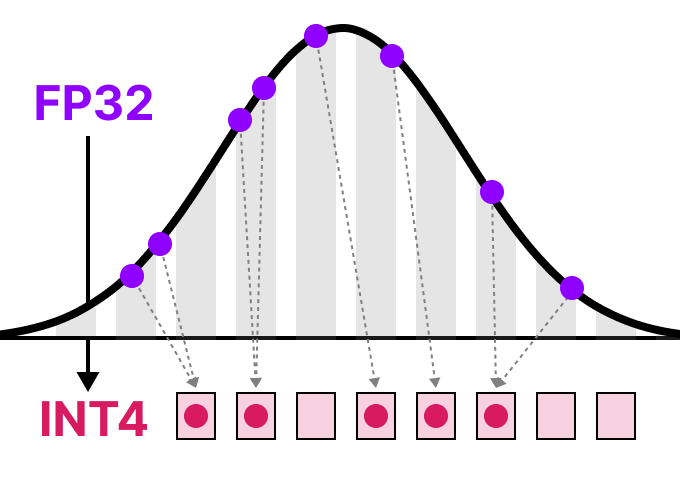
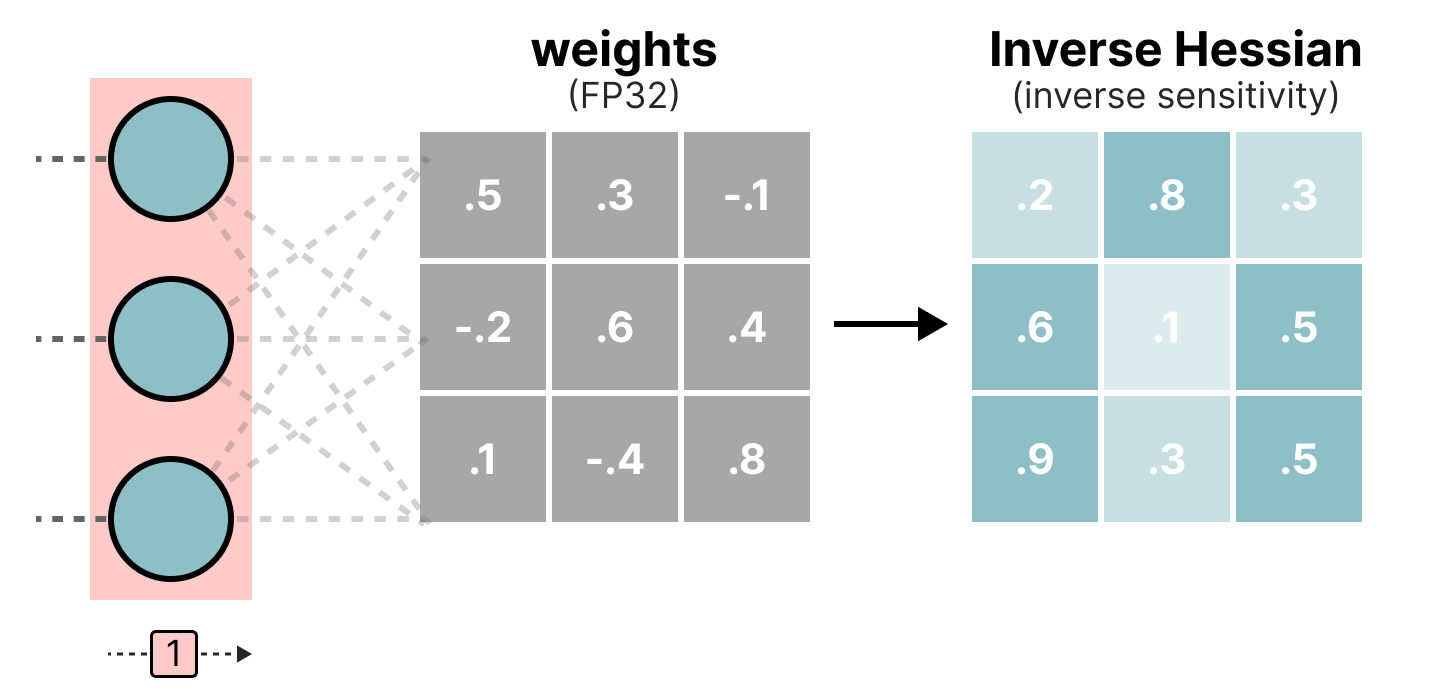
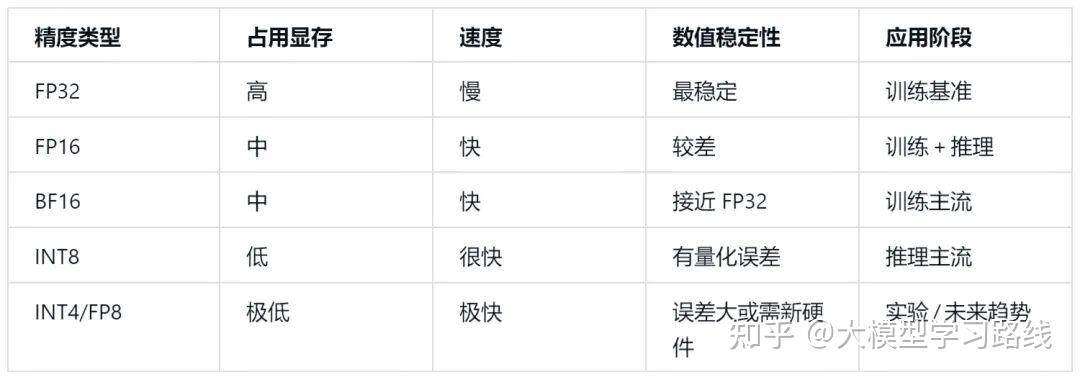
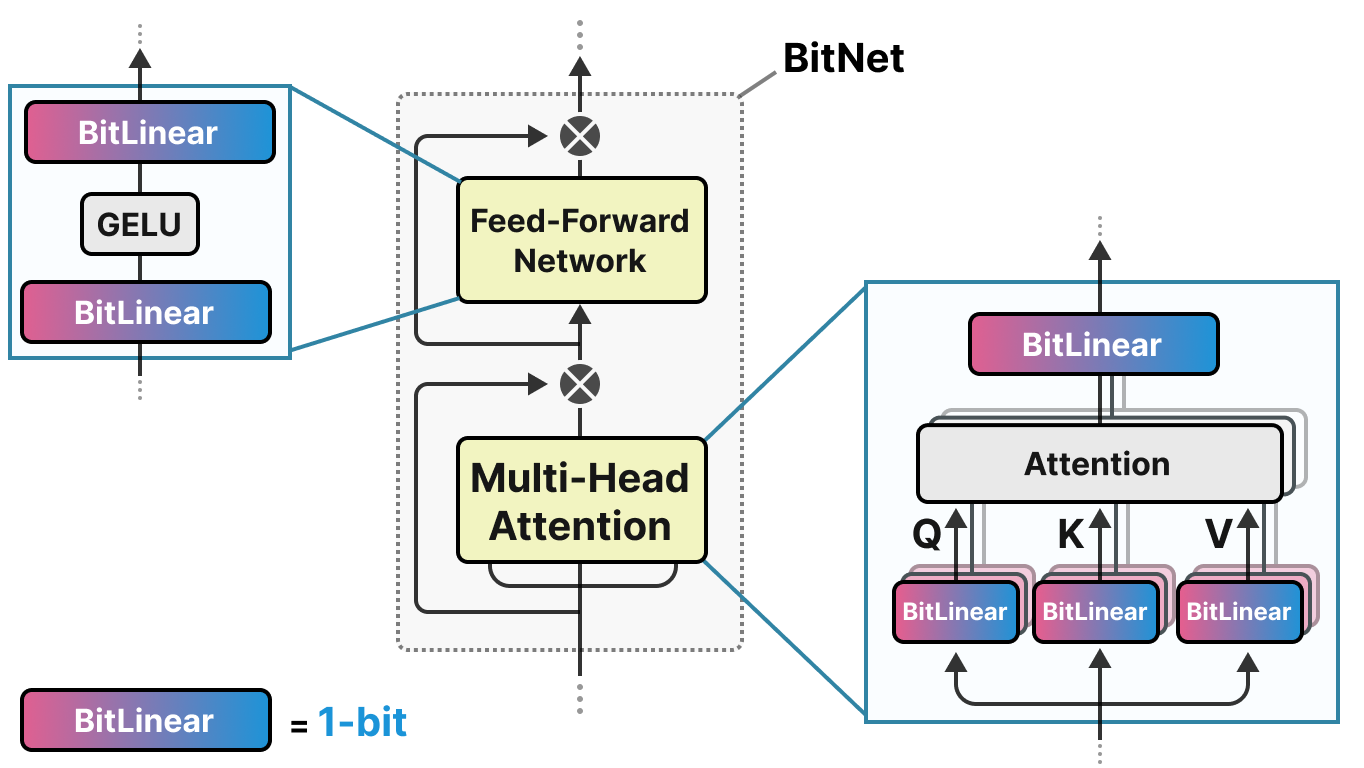
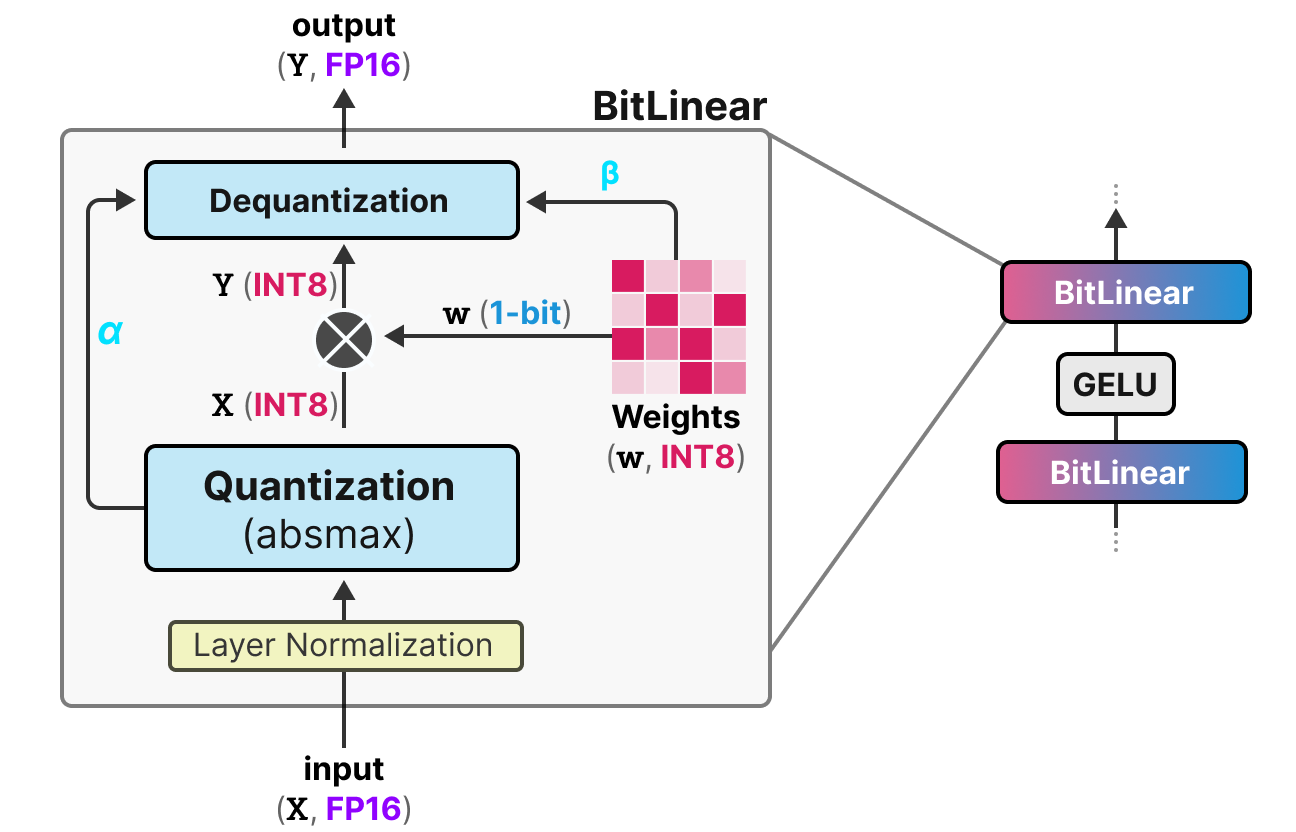
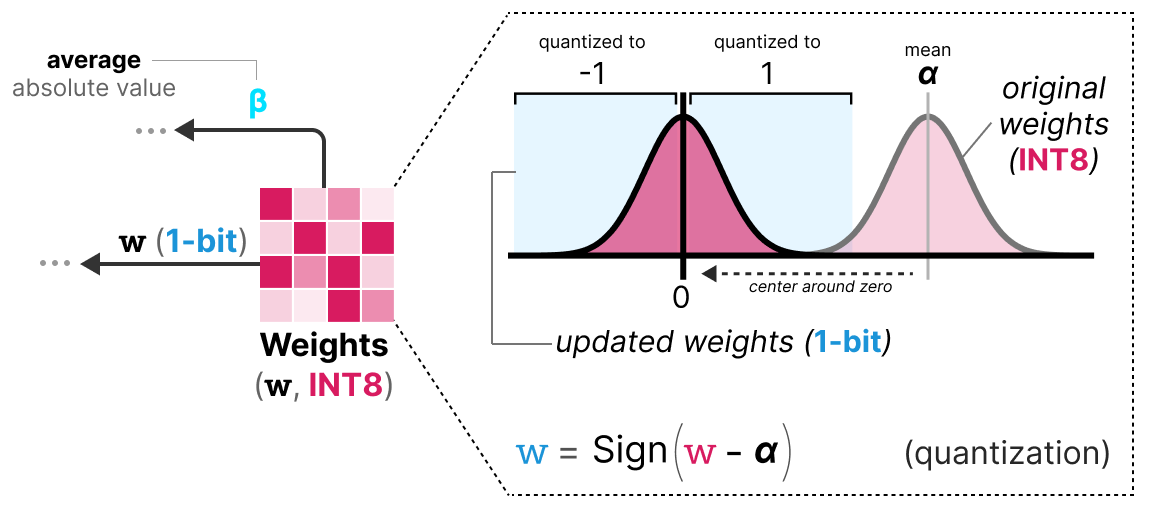
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
A Method of Deep Learning Model Optimization for Image Classification ...
神经网络INT8量化~部署_tensorrt树莓派-CSDN博客
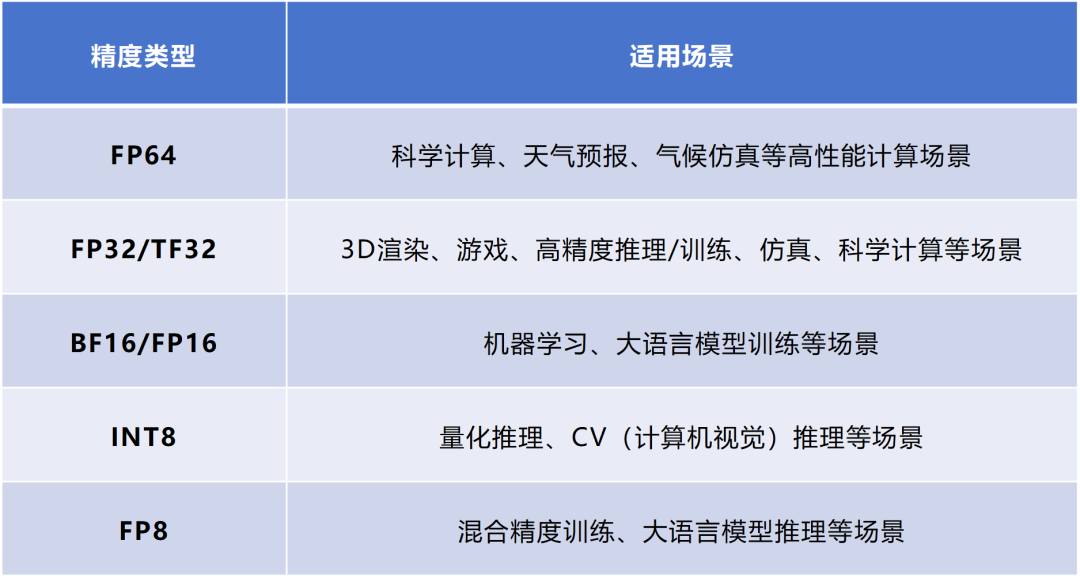
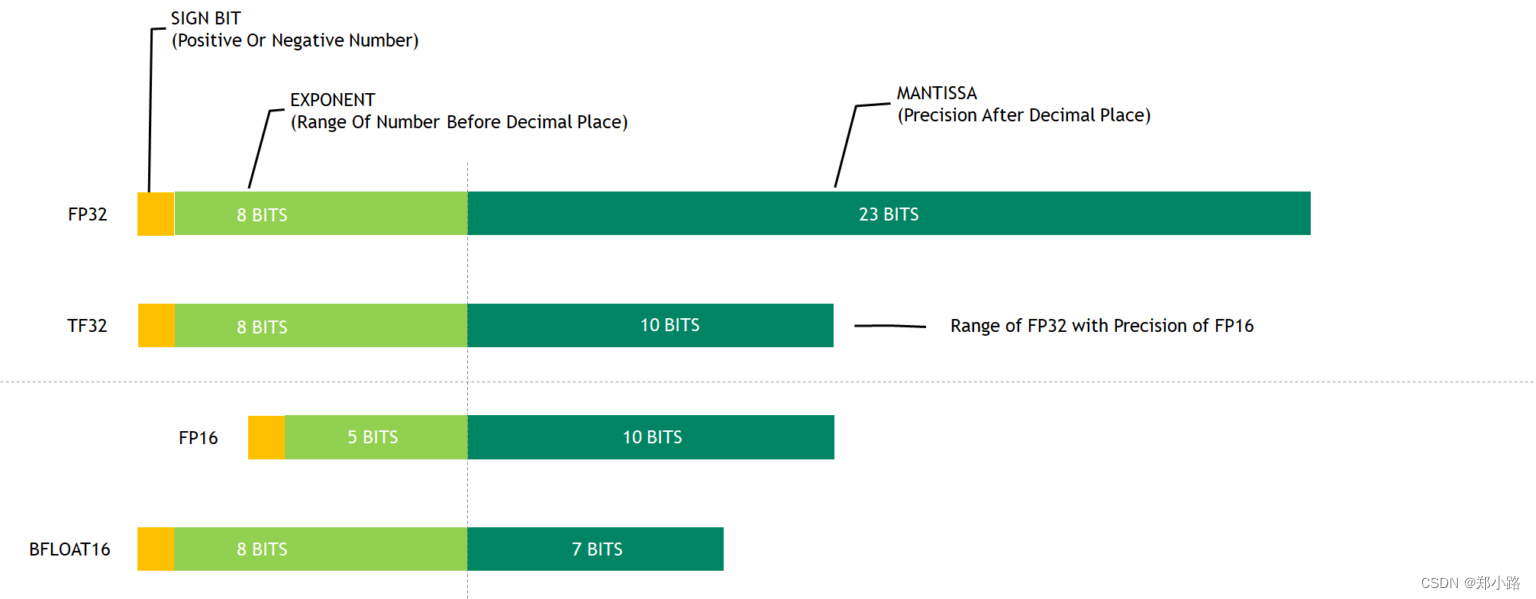
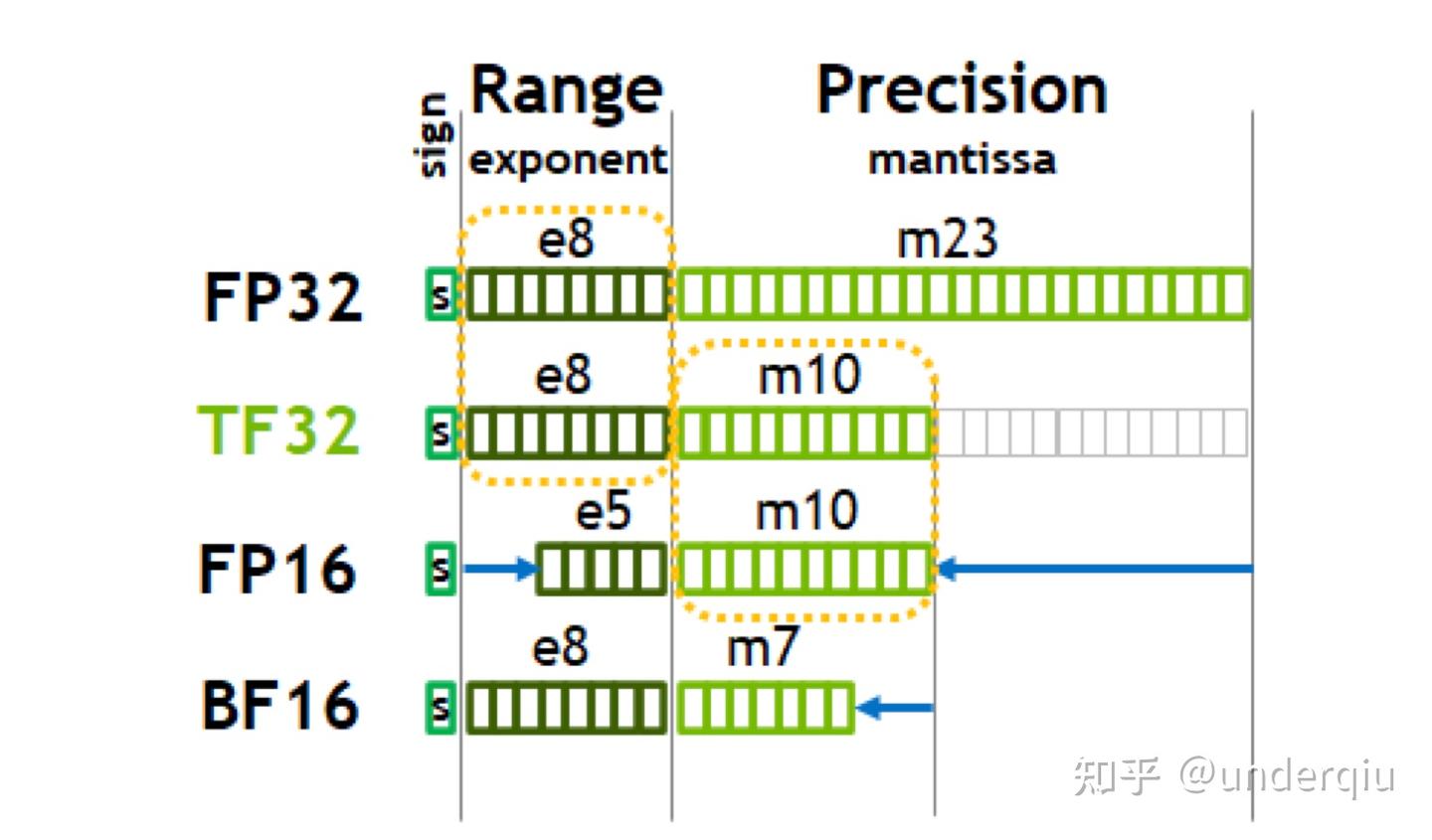
大模型精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8 - 知乎
FP8: Efficient model inference with 8-bit floating point numbers ...
部署系列——神经网络INT8量化教程第一讲! - 知乎
小白也能懂!INT4、INT8、FP8、FP16、FP32量化-CSDN博客
大模型中的计算精度——FP32, FP16, bfp16之类的都是什么???_混合精度训练和fp32的区别-CSDN博客
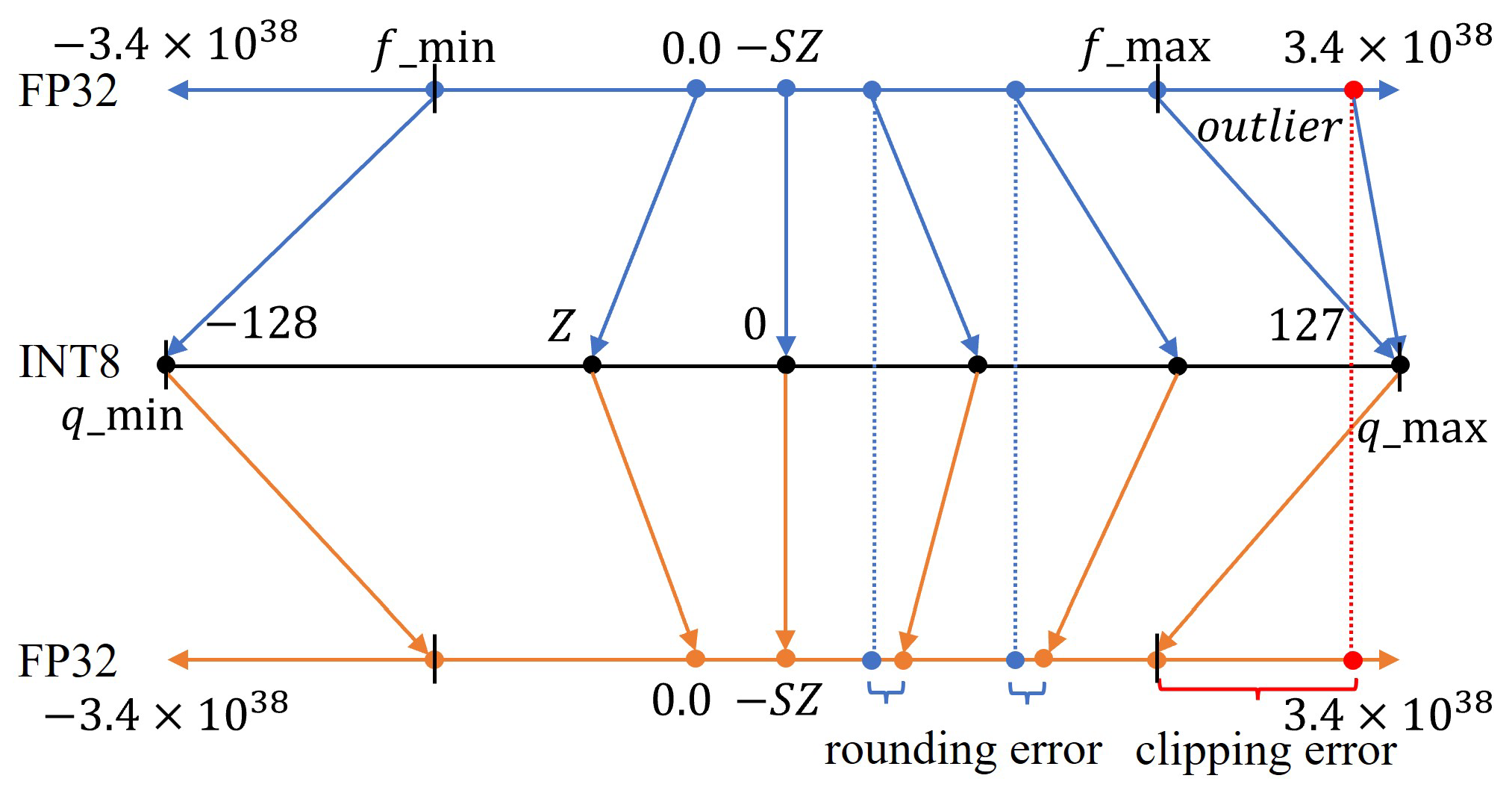
TensorRT下FP32转INT8的过程_fp32量化为int8-CSDN博客
FP16\FP32\INT8\混合精度的含义-CSDN博客
TensorRT模型转换及部署,FP32/FP16/INT8精度区分_tensorrt engine in fp16-CSDN博客
大模型涉及到的精度是啥?FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8区别_fp4和fp8-CSDN博客
TensorRT下FP32转INT8的过程_Tiso-yan的博客-CSDN博客
小白必读:到底什么是FP32、FP16、INT8? - 知乎
【干货】大模型算力优化全攻略——FP32、FP16、INT8数据格式精讲与实战应用_fp16和fp32-CSDN博客
Floating-point Arithmetic for AI Inference: Hit or Miss? - Edge AI and ...
【科普】大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析 - 53AI-AI知识库|企业AI知识库|大模型知识库 ...
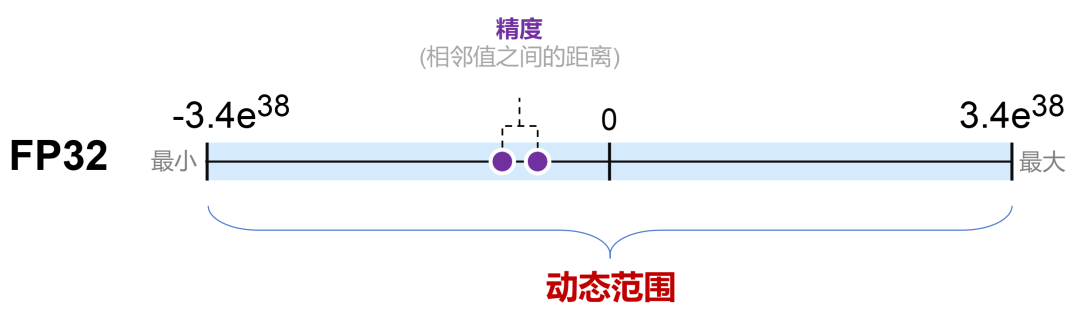
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
Quantization Methods for 100X Speedup in Large Language Model Inference
【AI Shift Advent Calendar 2023】図解!大規模言語モデルにおける 8bit 量子化入門 | 株式会社AI Shift
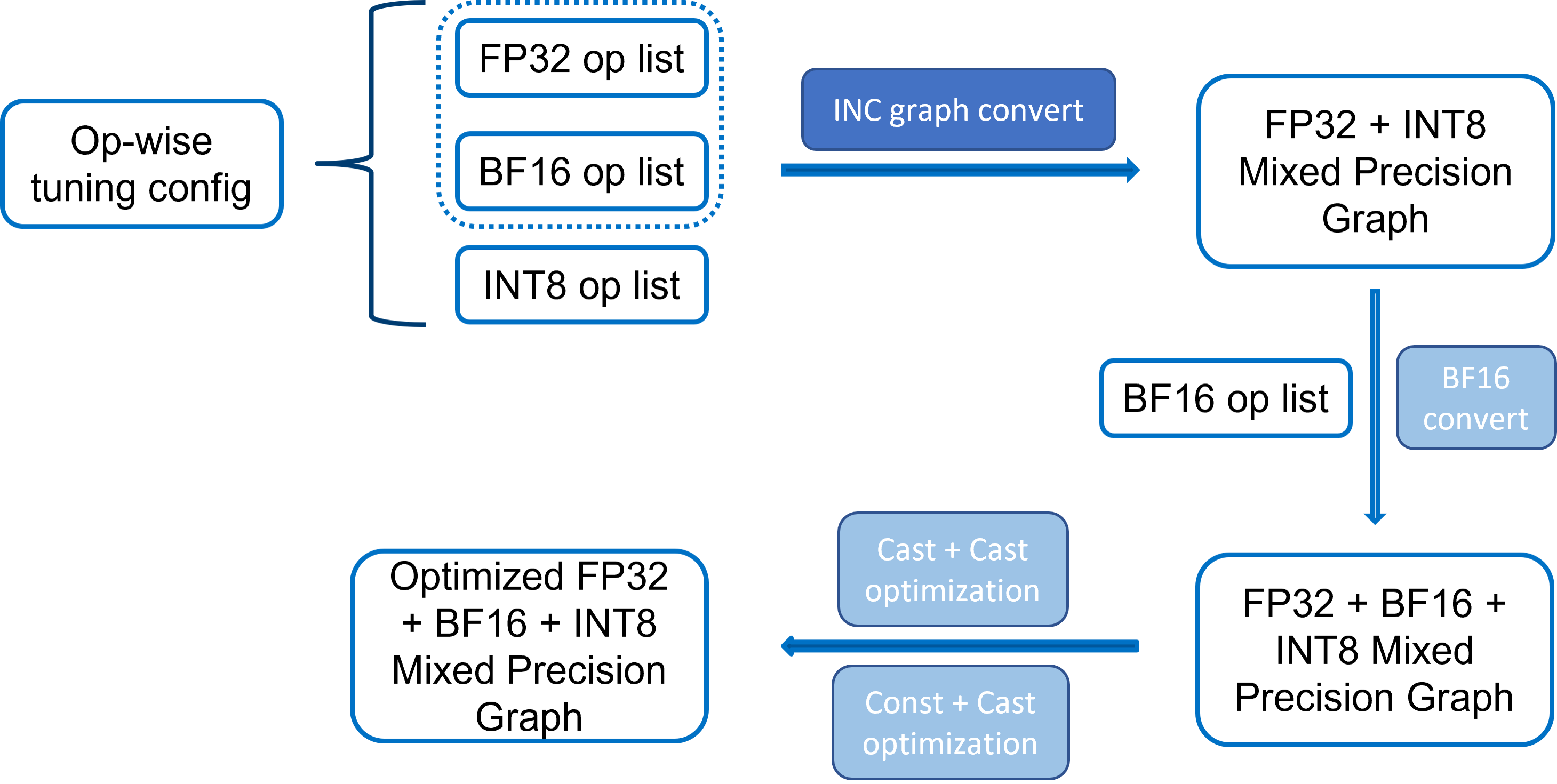
Turn ON Auto Mixed Precision during Quantization — Intel® Neural ...
Automatic Mix Precision | MindSpore 2.0 Tutorials | MindSpore
TensorRT:INT8量化加速原理与问题解析_tensorrt int8-CSDN博客
Сравнение различных схем квантования для LLM / Хабр
大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析_顺其自然~-MCP技术社区
FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep ...
FP32、FP16、INT8、Q4_K_M… 模型精度术语全解析 | AI铺子
什么是大模型的精度?大模型精度优化秘籍:FP32到INT8转换全解析! - 知乎
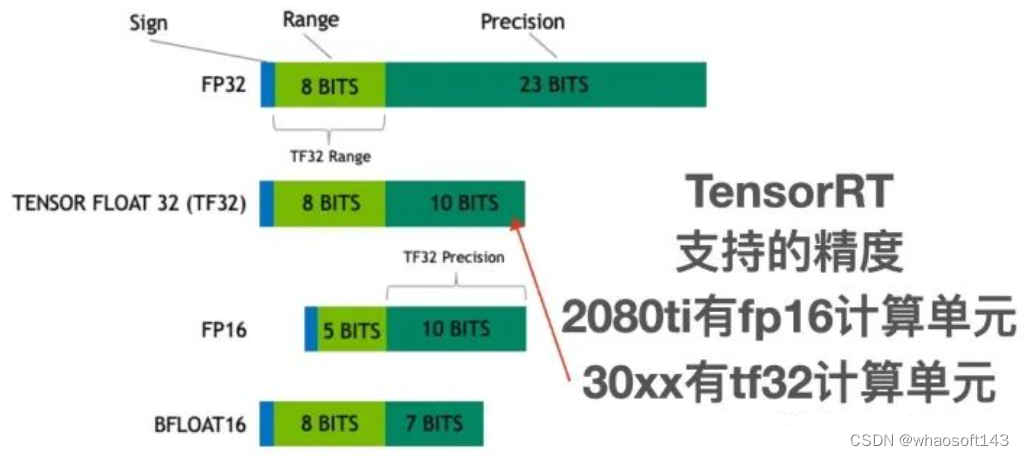
Deep Learning Performance Characterization on GPUs for Various ...
小白必读:到底什么是FP32、FP16、INT8?__财经头条
FP32、FP16、INT8精度相关 · Issue #680 · PaddlePaddle/FastDeploy · GitHub
FP32, BF16,int8, int4的区别 - 知乎
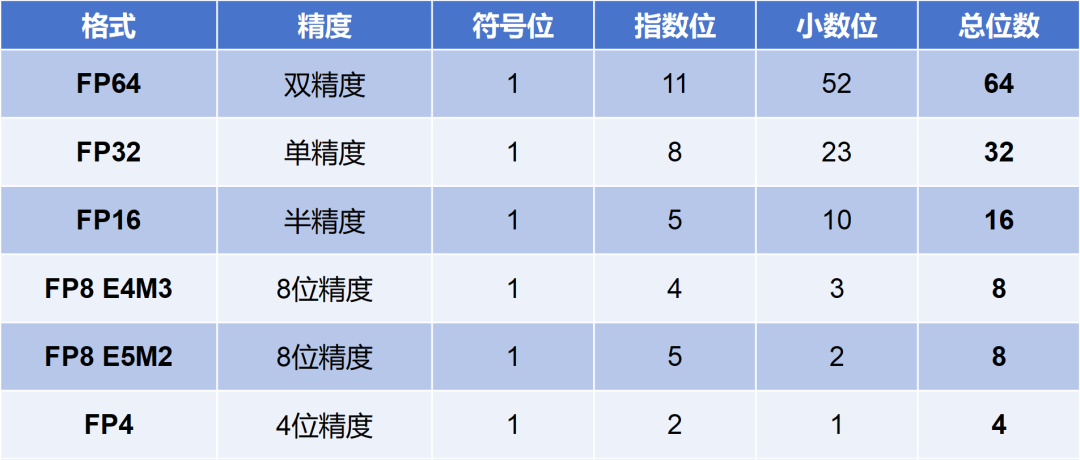
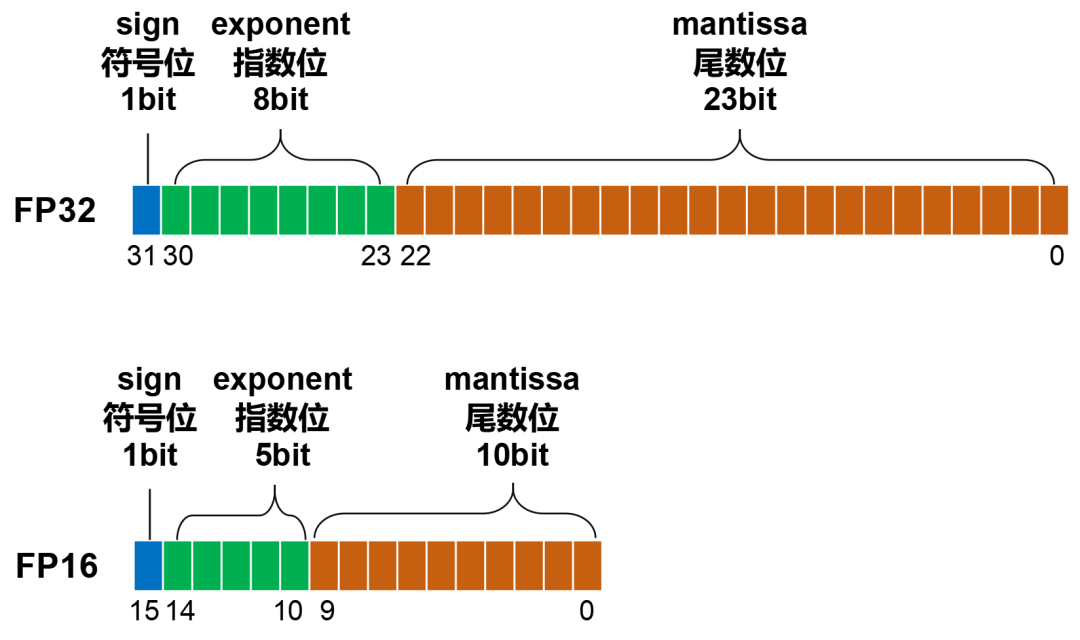
FP64、FP32、FP16、FP8简介-CSDN博客
模型精度问题(FP16,FP32,TF32,INT8)精简版_fp32、fp16、int8、tf32-CSDN博客
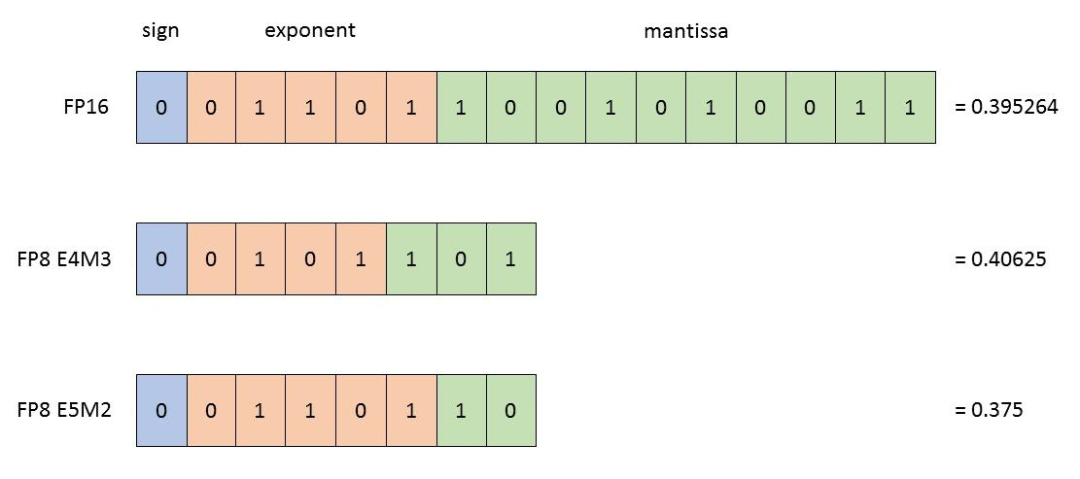
FP8 量化:原理、实现与误差分析-技术圈
从一次面试搞懂 FP16、BF16、TF32、FP32 - 知乎
FP16、FP32、INT8、混合精度-CSDN博客
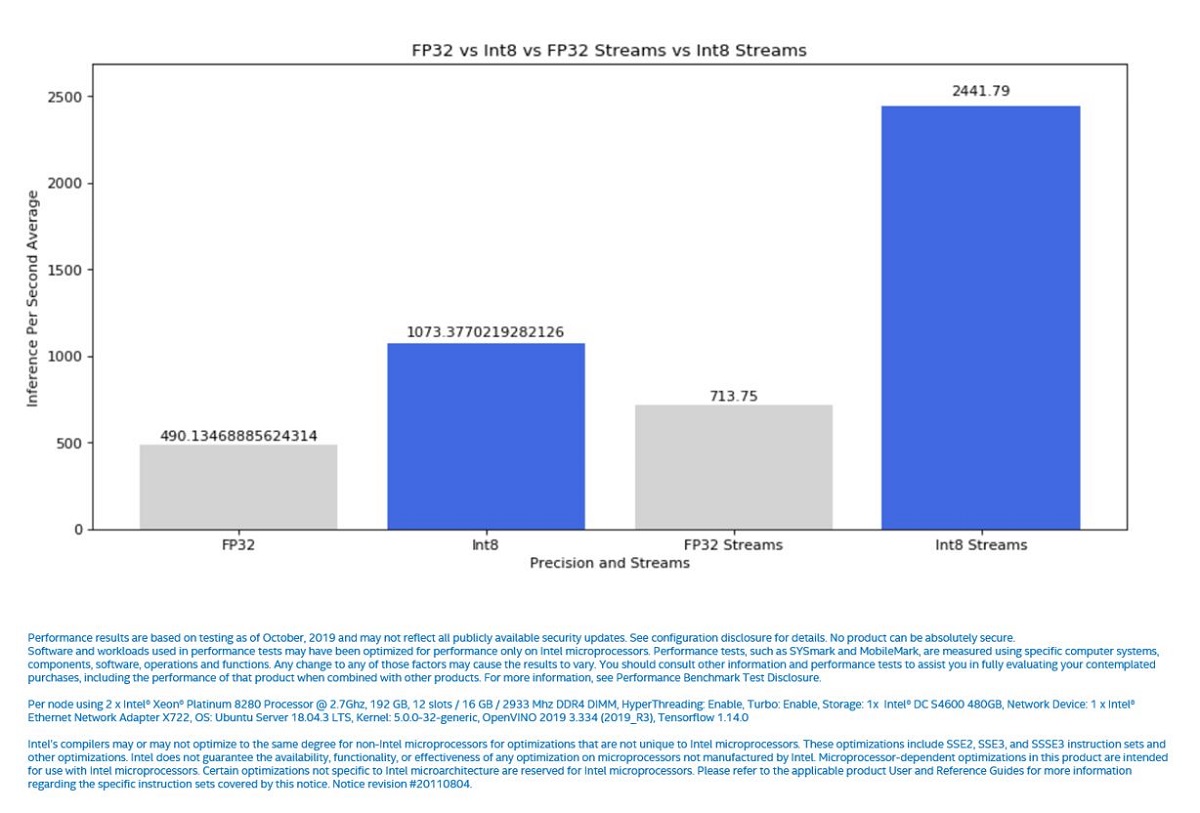
Get Started with Intel® Deep Learning Boost and the Intel®...
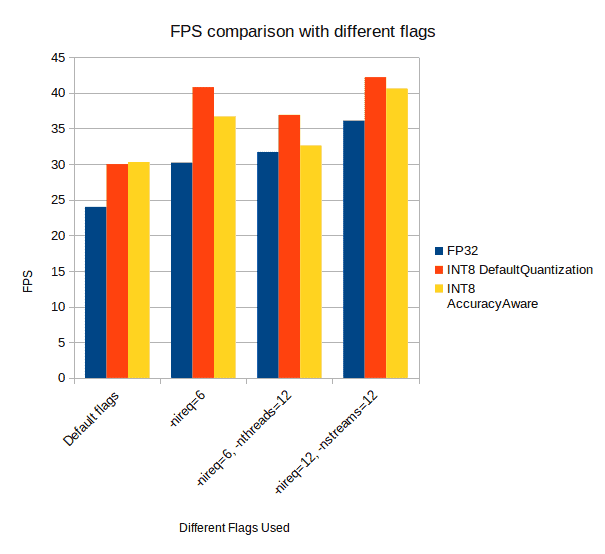
Introduction to OpenVINO Deep Learning Workbench LearnOpenCV
小白也能懂!INT4、INT8、FP8、FP16、FP32量化_独钓渔的技术博客_51CTO博客
Performance models in RunwayML with Intel Deep Learning Reference...
FP32,FP16以及Int8的区别?FP 深度学习 高性能计算 液冷服务器 @西安电子科技大学 @广西大学 @中南大学湘雅医院-度小视
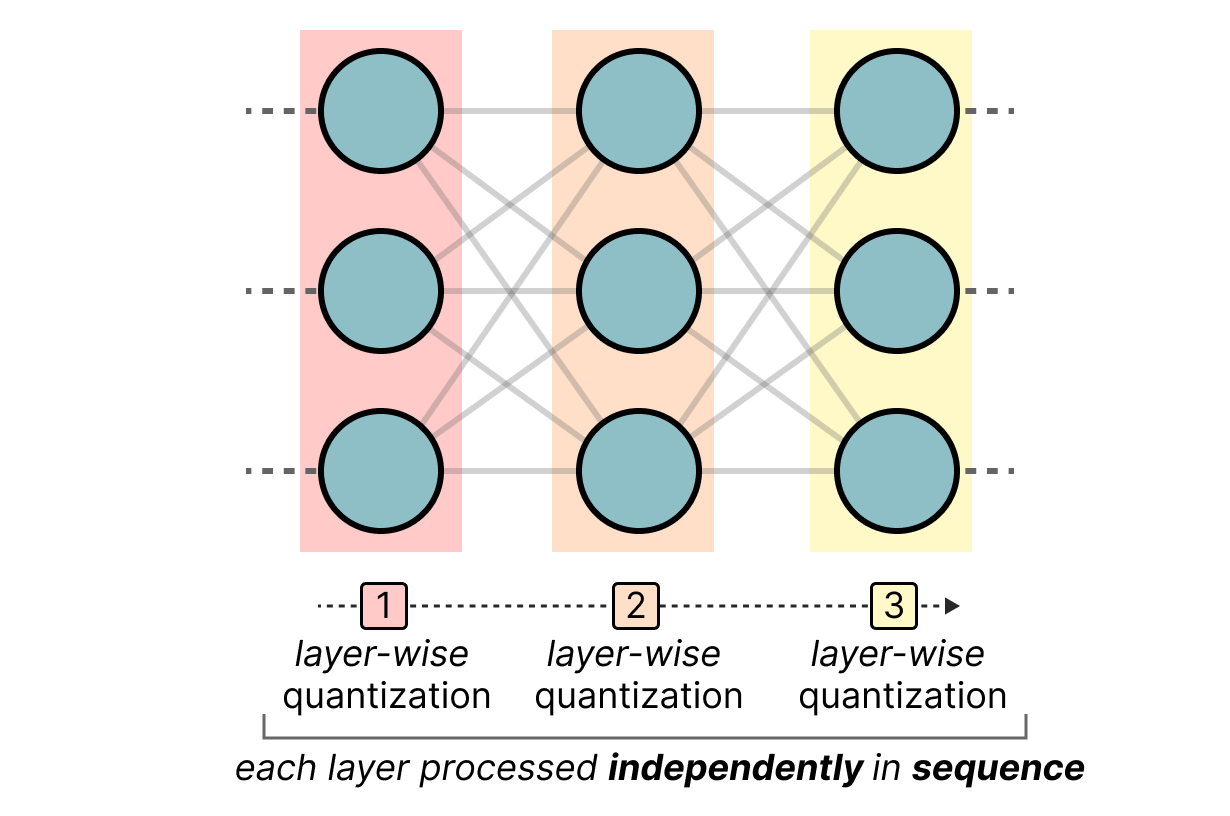
利用TensorRT实现INT8量化感知训练QAT_tensorrt int8量化-CSDN博客
Systolic Arrays and Structured Pruning Co-design for Efficient ...